In the previous article I’ve explained the migration logic and here I’ll see the implementation and some results using MongoDb as target db. I’m using official Mongodb Driver for .NET (2.0). Here is all the document model:
namespace SQL2MongoDB.Models
{
public class MongoProduct
{
public string Code { get; set; }
public string Description { get; set; }
public double Price { get; set; }
public long IdCategory { get; set; }
public IList<string> Synonims { get; set; }
public IList<ProductAttribute> Attributes { get; set; }
}
public class ProductAttribute
{
public string Key { get; set; }
public string Value { get; set; }
}
}
Very neat.
I don’t use any Id field logic and let Mongo create it for me.
All the migration logic is inside the specific MongoDbClient. I want to highlight three aspects about that:
- I don’t need any particular initialization logic
- XML-to-JSON mapping is natural
public void Save(SQLProduct dbProduct) { Contract.Requires<ArgumentNullException>(dbProduct != null, "dbProduct"); var product = new MongoProduct { Code = dbProduct.Data.Code, Description = dbProduct.Data.Description, IdCategory = dbProduct.Data.IdCategory, Price = Math.Round(10 + rnd.NextDouble() * (1000 - 10),2), Synonims = dbProduct.Synonims.ToStringList(), Attributes = dbProduct.Attributes.ToProductAttributes() }; products.Add(product.ToBsonDocument()); } - Post-migration logic is where I put the indexes creation. Why? I did some tries and found out that these indexes make my queries faster,but that’s not the point: normally migration procedures does NOT have code for online application logic (and they shouldn’t have), but for this scenario it could be good. Considering a normal legacy application, NoSQL db could be (initially) seen as a read-model where to transfer the RDBMS (denormalized) data and, if this transfer is pretty fast, it could be executed periodically from scratch, after dropping the whole collection, keeping the legacy application for the write-model.
But is the migration pretty fast? Here is the console log in my laptop
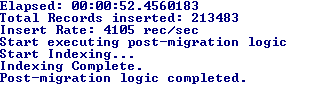
Not bad!
Queries
Ok. After that the MongoDb was populated I began to try some queries for multi-attribute catalog and after a while I found this as best queries:
Query for all product attributes (~2300ms)
db.Products.aggregate([
{$unwind: "$Attributes"},
{$group: { _id: "$Attributes", total: {$sum: 1} }},
{$sort: {"_id.Value":1}},
{$group: { _id: "$_id.Key", Properties: {$push: {Value:"$_id.Value", Count:"$total"}}}},
{$sort: {_id:1, "Properties.Value": 1}}
]);
Query for product attributes filtered by some attribute values (~170ms)
db.Products.aggregate([
{$match: {
$and: [
{"IdCategory":245710},
{"Price":{$gte: 100, $lt: 400}},
{$and: [{"Attributes.Key":"FORMATO"}, {"Attributes.Value":"0402 (1.0 x 0.5mm)"}]},
{$and: [{"Attributes.Key":"TOLLERANZA"}, {"Attributes.Value": {$in: ["± 0.01%","± 0.05%","± 0.1%"]}}]}
]
}},
{$unwind: "$Attributes"},
{$group: { _id: "$Attributes", total: {$sum: 1} }},
{$sort: {"_id.Value":1}},
{$group: { _id: "$_id.Key", Properties: {$push: {Value:"$_id.Value", Count:"$total"}}}},
{$sort: {_id:1, "Properties.Value": 1}}
]);
Query for documents filtered by some attribute values (~ 26ms)
db.Products.find({
$and: [
{"IdCategory":245710},
{"Price":{$gte: 200, $lt: 400}},
{$and: [{"Attributes.Key":"FORMATO"}, {"Attributes.Value":"0402 (1.0 x 0.5mm)"}]},
{$and: [{"Attributes.Key":"TOLLERANZA"}, {"Attributes.Value": {$in: ["± 0.01%","± 0.05%","± 0.1%"]}}]}
]
})
.limit(10)
Pros
- Clear. Readable. Maintainable
- the query results give the complete structured json object, with the nested couples of attribute's value/count. There's no need to manipulate furthermore the object in front-end code
- Pretty fast, specially for filtered query
- Migration time is very good
Cons
- Not so speed as I guess...specially for Query for all product attributes. MSSQL Stored procedures took roughly the same time (in same machine).This is the point to stress; I tried different indexes combinations, but I was not able to improve performance furthermore...maybe some suggestion?
Comments