In the previous article, I was asking myself «how does NEventStore work with legacy systems?». Here again I’m asking myself which kind of strategies could I implement to migrate data from Legacy System (n-tier) to CQRS+ES?
From the data-layer perspective, here is the scenario I’m talking about:
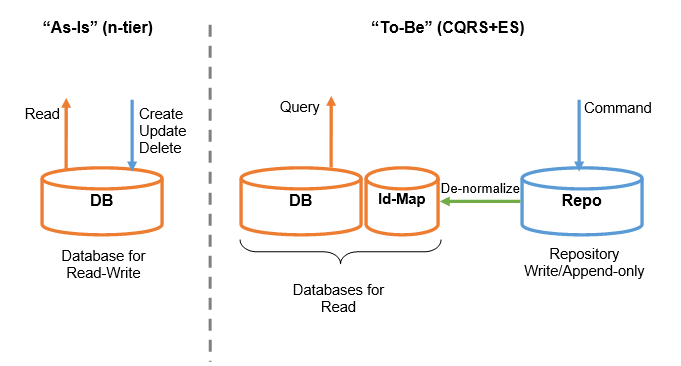
That’s:
- I’d like to keep the same structure of the legacy database for my Read-model. Probably this is not the best practice (because the legacy database could not be optimized for reading, as CQRS+ES allows to have), but it should minimize the rework on the presentation layer or external systems, specially if we have exposed the IDs (in URL, API or wherever)
- I need some Ids-map for mapping NEventStore GUID with existent ids
Migration Strategies
Despite all the variants that anyone could think, I can see two kind of approaches:
- Migration Domain Event: probably this is the “NEventStore way” to approach this kind of migration. It means to create a line of “command-event” to initialize the AggregateRoot state reading all the data from legacy database; from the implementation point of view it’s exactly the same of creating new command-event for your AR; these events will begin the history of your ARs hereafter
- Fake-Snapshots: working with an event-store also this approach involves the creation of events, but in this case I’m talking about external (No-Domain) events that are immediately followed by an Aggregate Snapshot that exploits the Aggregate Memento.
Let’s dive into the second option.
Fake-Snapshots
This approach is realized by this logic:
- Every entity not yet migrated is an entity (in the target database) without an Id-Mapping. So this kind of check could drive the whole migration flow, allowing us to parallelize the migration or quit-and-resume the migration.
foreach (var list in _database.ToDoLists) { if (_db.IdMaps.GetAggregateId<ToDoList>(list.Id).Equals(Guid.Empty)) { // Migrate entity } } - I retrieve a not used ID for the IDs-mapping
// Get fresh new ID Guid entityId = Guid.NewGuid(); while(!_db.IdMaps.GetModelId<ToDoList>(entityId).Equals(0)) entityId = Guid.NewGuid(); - Create a Memento entity from the readmodel data
// Create Memento from ReadModel var entity = new Todo.Domain.Model.ToDoListMemento(entityId, 1, list.Title, list.Description); - Create a fake External event. This is how I trick the NEventStore’s snapshooting policies, because NEventStore does NOT allow you to create a snapshot not connected to a commit. This makes sense to me, but during the normal life of an AR, if we’ll create snapshots and then we’ll retrieve the AggregateRoot by Id, NEventStore will retrieve the AR from Snapshot through the memento pattern and it will re-tape all the next events, WITHOUT checking for the existence of the commit connected to the snapshot…so…maybe this approach is not so ugly…
// Create a fake External event using (var stream = _store.OpenStream(entityId, 0, int.MaxValue)) { stream.Add(new EventMessage { Body = entity }); stream.CommitChanges(Guid.NewGuid()); } - Now I create the snapshot with the data enveloped into the specific Memento class
// Save Snapshot from entity's Memento image _store.Advanced.AddSnapshot(new Snapshot(entity.Id.ToString(), entity.Version, entity)); - At the end I create the IDs-mapping
// Save Ids mapping _db.IdMaps.Map<ToDoList>(list.Id, entityId);
Some consideration
What I like in this approach is that I kept completely separated the domain from the migration logic. Nothing about the migration is present in the Domain or Command/Query stacks. That’s the point in my opinion: the migration is the beginning of all of your existent ARs, but it’s not relevant in terms of business-domain, it’s more like a technical step, so this kind of code should not pollute the business code (wait, I’m not saying that migrations do not involve some domain expert’s decisions, but these are decisions that generally do not impact on the normal life of the ARs after the migrations).
Migration are very complex projects, often realized by specific teams, sometimes different from business dev teams. In my experience I worked in dev team on some very complex domains, while some different teams were working on a migration project on the same production environments (think about a multi-tenant environment with a roll-out plan for different “go-live”). I didn’t know their logic; they didn’t know mine; but the database structure and its rules were in common in the same time. Keep the code separated was a must. Again, these are my thoughts and my solution; I’m not sure is the best and I’m open to learn from your experience and ideas.
If you are interested, all the code is present in the repository under a specific project (Todo.Legacy.Migration), but DI’s container specific installer and migration invocation, but just for the sake of this training journey. All the code about migration is visible in this commit.
Update - 20/10/2014
Recently I’ve reviewed the last part of the migration strategy, cause I wanted to make some practices about Events-Replaying. Actually doing some experimentation about replaying the committed events (necessary for example to recreate a projection) allowed me to figure out an important error in this strategy: the migration event should be able to be listened (and rebuilt) by the read-model event-handlers.
That’s why if we didn’t have an event-handler for that external events, the projection was not able to be correctly rebuilt, because it couldn’t re-create the migrated entities and, afterwards, the next committed events could not be correctly handled. So the migration logic was be modified in two points:
- Memento Propagation events: migration events were added in order to propagate the initial state of the Aggregates (from migration) to read model projection.
- Memento Propagation events Handlers: the handlers were added. Some migration logic could be managed in these handlers, but I prefer to keep migration logic in Migration manager and leave in these handlers only the logic necessary for rebuilding task.
here the code for the reviewed migration strategy.
Some final consideration
The last update introduced something that could be considered an “open point”. The migration event should carry a complete state of the AggregateRoots from previous system. To do that I consider reasonable to use a Memento as the event’s single property. This kind of event could be named to give a full meaning of the Migration process (i.e. MigratedToDoListeEvent) or with a more general name, that could be used also for maintenance purposes. For example to introduce some data-fix (cause bugs or whatever) in the events sequence. This is something like a “return to CRUD logic”, using events without a specific domain meaning, but…it’s convenient, and easy, and just for devops team.
Comments